Run Open Source LLMs Locally with LM Studio
Running LLM models locally on your own machine is a game-changer. For many tasks, there is no need to depend on cloud services like OpenAI and Claude. Then there are advantages like data privacy, no API costs and the ability to run models offline on your machine.
In this guide, we will look at setting up LM Studio and running open-source models locally.
Getting Started with LM Studio
LM Studio provides a GUI interface for downloading and running open-source language models. Here's how to get up and running:
Download and Install LM Studio
Visit the LM Studio website and download the appropriate version for your operating system. Run the installer and launch the application
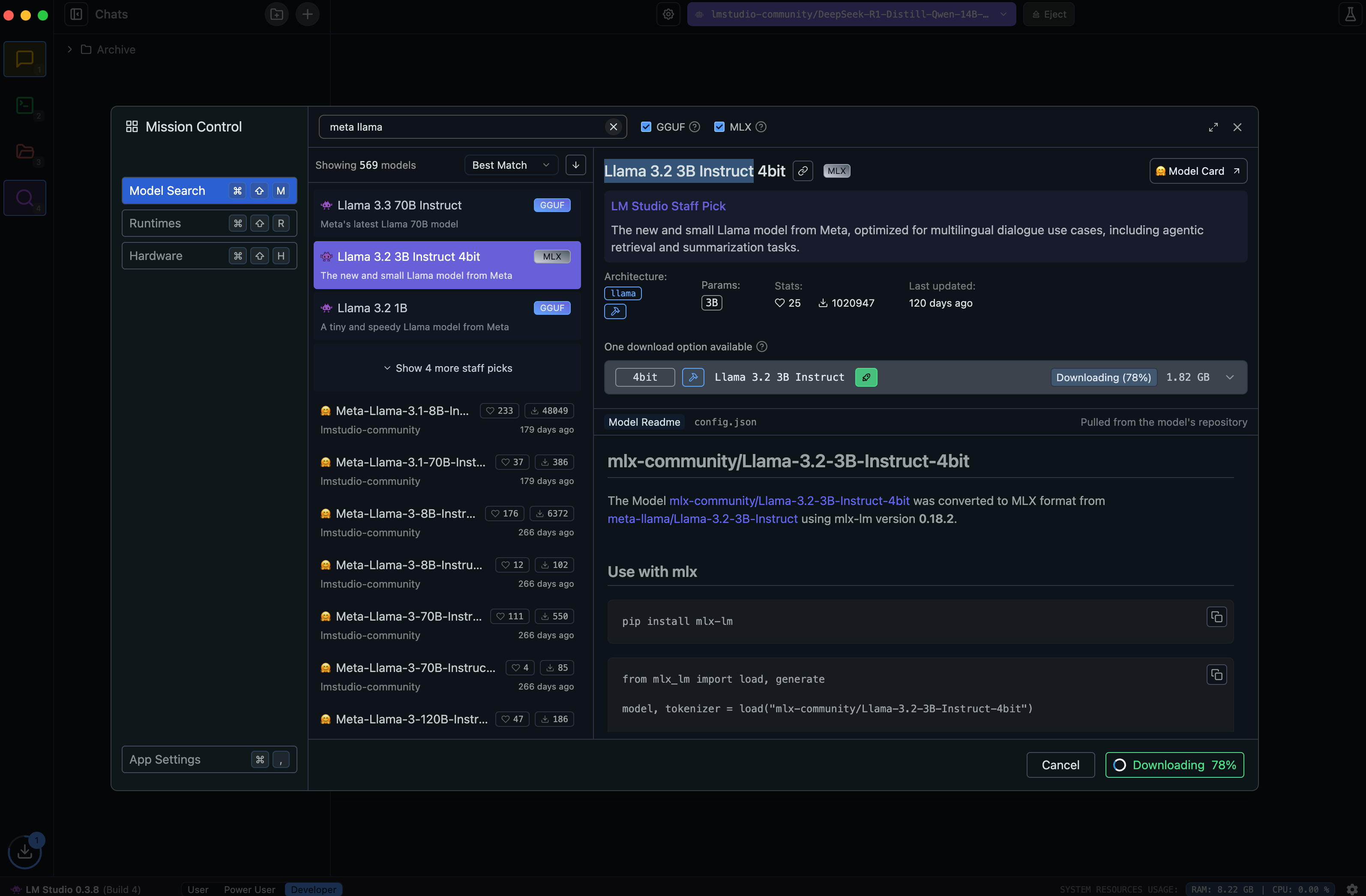
Choose Your Model
LM Studio integrates directly with HuggingFace, giving you access to popular open-source models like Meta's open-source Llama models and Deepseek models – which are all the rage currently.
On a typical machine, you can go with 7B parameter models or even 14B if you have a large amount of RAM (e.g. 32GB). I have been able to run Deepseek's 14B model on an M1 Pro with 32GB RAM.
Performance will vary depending on your hardware. I recommend starting with a smaller model and then experimenting with larger ones as needed. For this example, I chose Llama 3.2 3B Instruct.
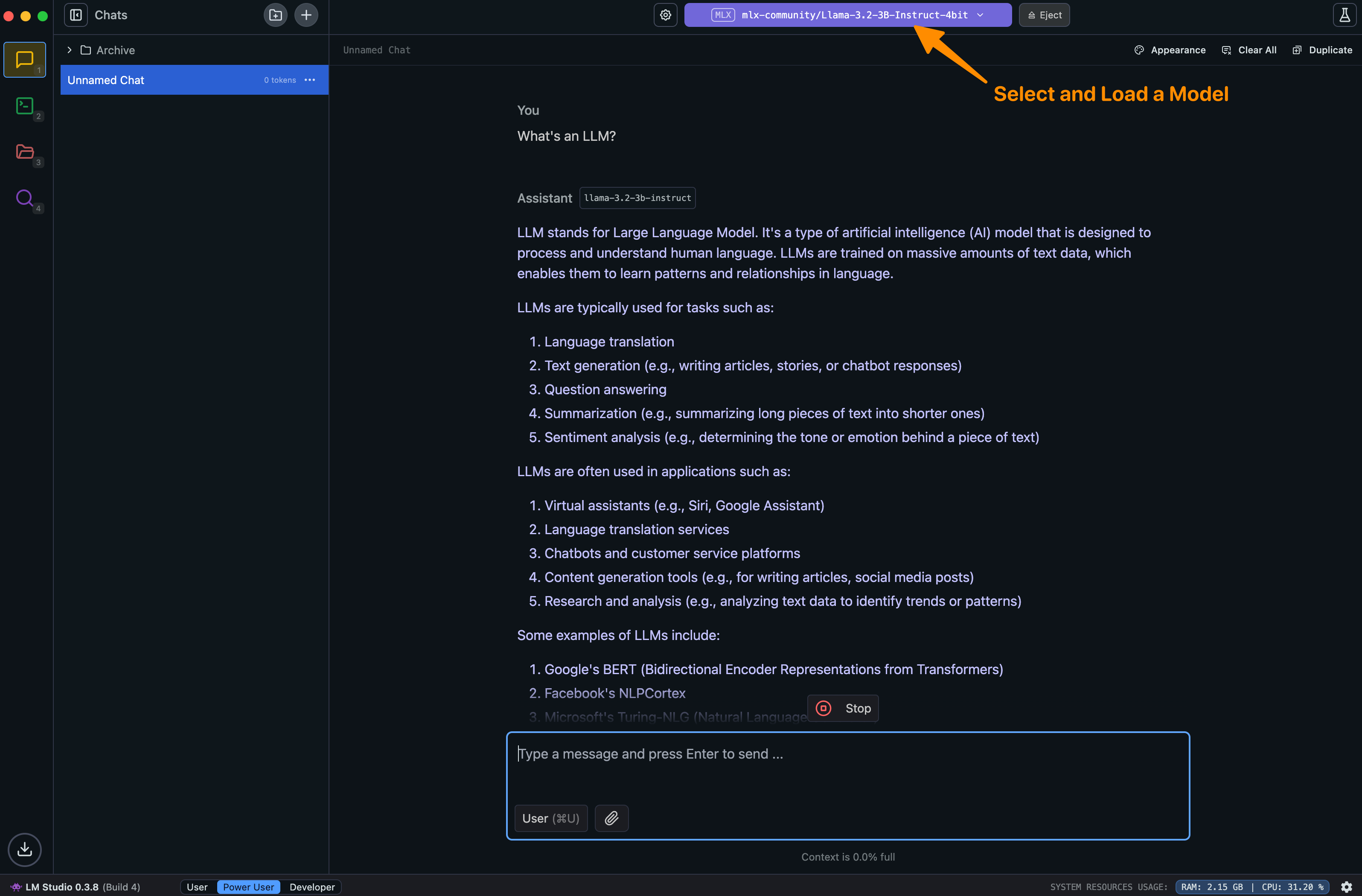
Load and Chat
On the top of the screen, select the downloaded model from the library and click "Load Model". Once the model is loaded, you can start a conversation by typing in the text box below. Easy!
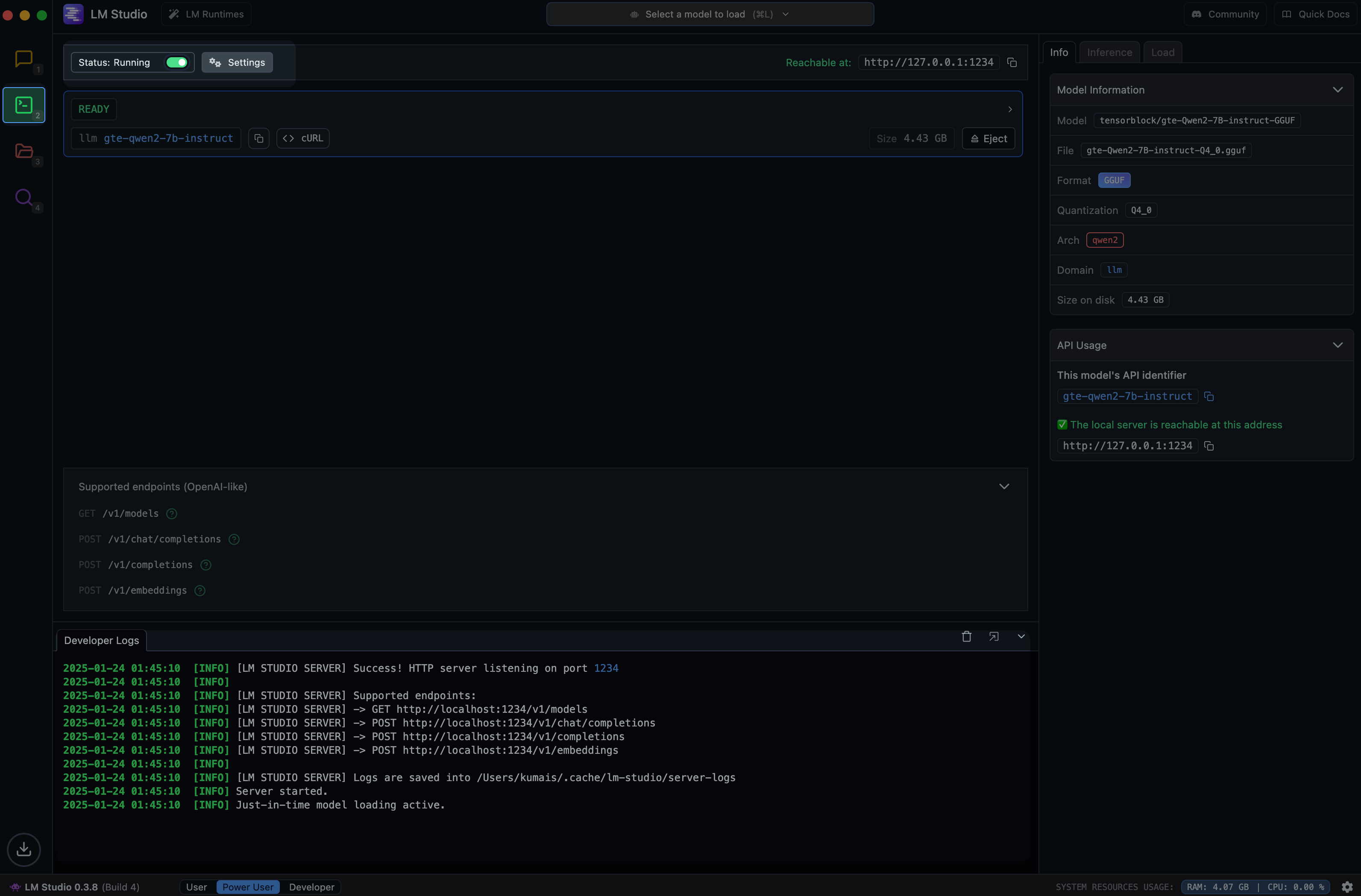
Use LM Studio as an API service
LM Studio also has a local LLM server that you can use as an API service. It has an OpenAI compatible API that is useful for testing LLM integrations when developing locally – without incurring any costs.
You can enable the server in the Developer section. This enables the following endpoints:
GET http://localhost:1234/v1/models
POST http://localhost:1234/v1/chat/completions
POST http://localhost:1234/v1/embeddings
POST http://localhost:1234/v1/completions
You can reuse your existing OpenAI SDK by switching the base url in your config to – http://localhost:1234/v1
A great use case for this is generating embeddings for your application. Running embedding models locally can significantly reduce costs and latency compared to OpenAI's embedding API.
I'll explore this in detail in another article.
Liked this article? Share it on X